Objective 9.1: Configure Advanced vSphere HA Features
Configure a network for use with HA heartbeats
La disponibilidad de la infraestructura de red es un punto importante a la hora de detectar problemas de conectividad en los servidores host, por lo que es importante disponer de una configuración de red robusta. Una de las opciones para proporcionar mayor disponibilidad a la red de administración es crear puertos VMkernel adicionales con la opción "Management network" habilitado. La configuración recomendada es utilizar 2 tarjetas físicas con configuración de Teaming, por ejemplo tener 1 vSwitch con los interfaces físicos (vmnic0 y vmnic1) El grupo de puertos VMkernel de administración puede tener como interfaz activo vmnic0 y como standby vmnic1.
Es también recomendable configurar más de una dirección de aislamiento utilizando la opción avanzada das.isolationaddressX
Apply an admission control policy for HA
Con Admission Control, vSphere HA se asegura que existen suficientes recursos en el cluster para proporcionar disponibilidad y asegurar que se respetan las reservas de recursos (CPU y memoria) configuradas en las máquinas virtuales. Admission control puede impedir:
- Encender una máquina virtual
- Migrar una máquina virtual
- Aumentar la reserva de CPU o memoria de una máquina virtual
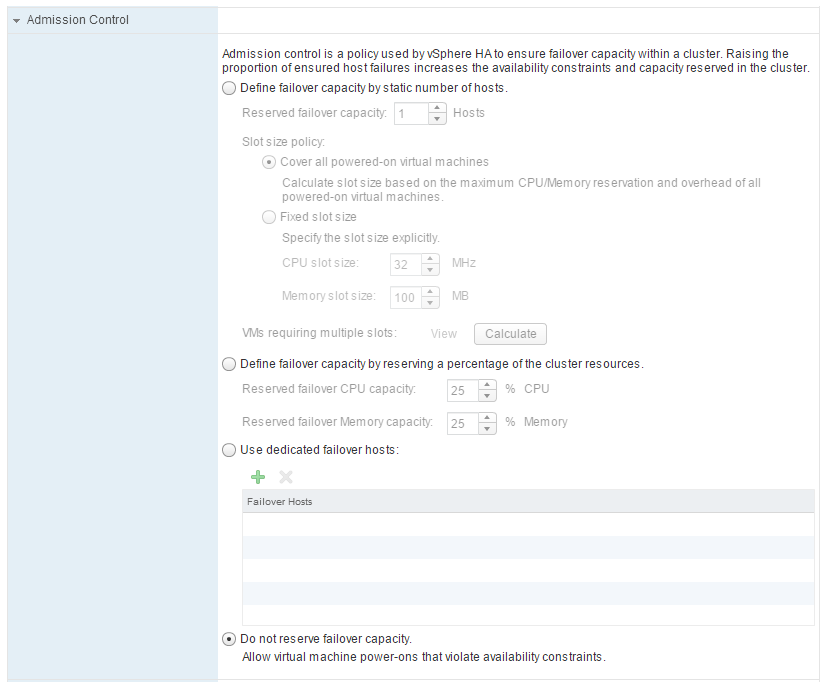
Opciones de configuración de Admission Control
- Host Failures Cluster Tolerates: se indica el número de hosts que se puede tolerar que fallen. En este caso, VMware calcula un tamaño de máquina virtual (o tambíen llamado slot) para determinar el número de slots que se pueden ejecutar en el cluster, teniendo en cuenta el número de hosts definidos que pueden fallar. El tamaño del slot se calcula para CPU y Memoria (también se puede establecer de forma fija en la configuración de Admission Control):
- CPU: lo calcula con las reservas establecidas en las máquinas virtuales. Si no hay ninguna reserva se establece un valor de 32Mhz
- Memoria: se calcula con el mayor valor de la reserva de memoria más overhead de las máquinas virtuales. No hay un valor predeterminado.
- Percentage of Cluster Resources Reserved: permite reservar los recursos en base a porcentajes de CPU y memoria.
- Failover Hosts: se configura explícitamente uno o varios hosts como stand-by, de forma que estos hosts solo ejecutan máquinas cuando el resto ha tenido algún problema.
Para configurar Admission Control seguimos estos pasos:
- Accedemos al cluster
- Accedemos a Manage -> Settings -> vSphere HA
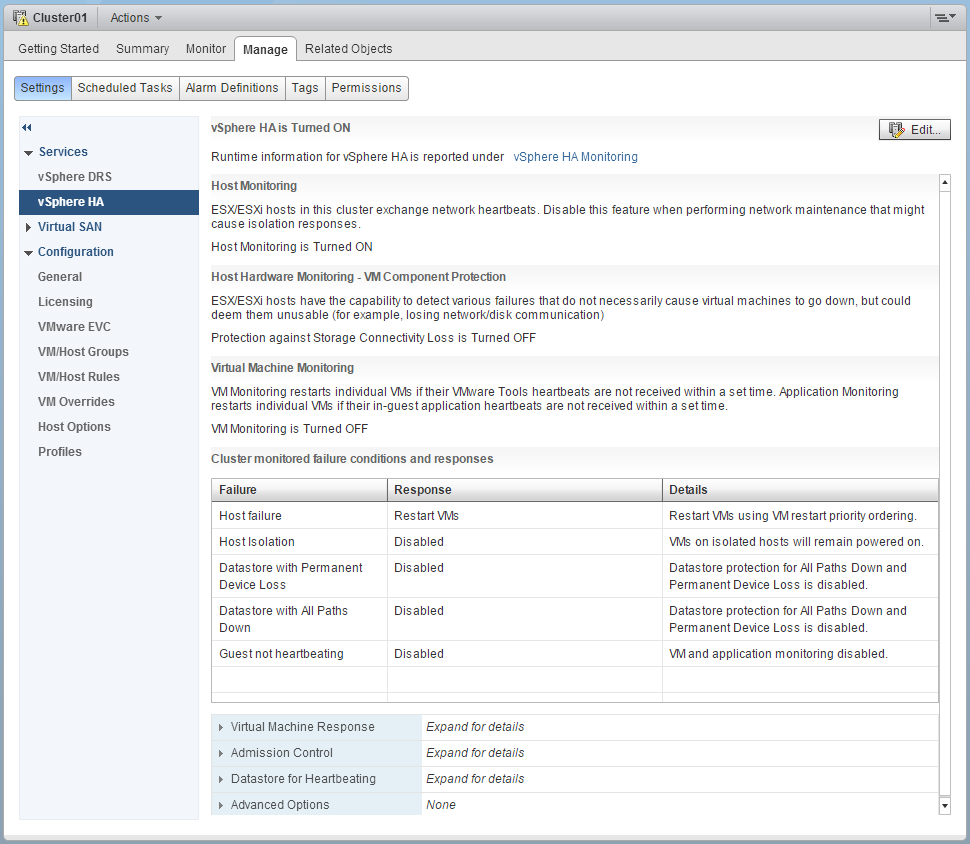
- Pinchamos en Edit
- Expandemos la opción Admission Control
- Configuramos la opción del tipo de Admission Control y los parámetros correspondientes
Enable/disable advanced vSphere HA settings
Podemos configurar de forma más detallada el comportamiento del cluster vSphere HA a través de las configuraciones avanzadas:
| Opción | Descripción |
|---|---|
| das.heartbeatDsPerHost | Modifica la cantidad de datastores requeridos para Heartbeat. Los valores aceptados son 2-5. Por defecto es 2. |
| das.ignoreInsufficientHbDatastore | Deshabilita los problemas de configuración generados si un host no tiene suficientes datastores de Heartbeat. El valor predeterminado es false. |
| das.slotCpuInMHz | Define el máximo de la configuración CPU del tamaño del slot para Admission Control. Si se utiliza, el tamaño del slot es el menor valor de este o la reserva de CPU máxima de las máquinas encendidas del cluster. |
| das.slotMemInMB | Define el máximo de la configuración de memoria del tamaño del slot para Admission Control. Si se utiliza, el tamaño del slot es el menor valor de este o la reserva de memeoria máxima de las máquinas encendidas del cluster. |
| das.config.fdm.memreservationmb | Define la cantidad de memoria reservada para la ejecución del agente vSphere HA (FDM) en los servidores hosts. Por defecto tiene un valor de 250 MB. Puede tomar un valor entero superior a 100. En clusters grandes (entre 6000 y 8000 maquinas) se recomienda configurar este valor a 325 |
| das.respectVmVmAntiAffinityRules | Determina si vSphere HA aplica las reglas de antiafinidad entre máquinas virtuales. El valor por defecto es false. Si se configura en true, vSphere HA no reiniciará una máquina virtual si ello implica infringir una regla de DRS existente. |
| das.maxresets | Define la cantidad máxima de intentos de reinicio realizados por VMCP aunte una situación APD. |
| das.maxterminates | Define la cantidad máxima de intentos que realiza VMCP para finalizar una máquina virtual. |
| das.terminateretryintervalsec | Define el tiempo en segundos entre un intento fallido de finalización de una máquina y el siguiente intento. |
| das.reregisterRestartDisabledVMs | Determina si una máquina que no está protegida por HA se registra en un host ante una caida de un servidor para facilitar su encendido. |
| das.isolationAddressX | Determina la dirección a la que se hará ping con el fin de determinar si un host está aislado de la red. Se hace ping a esta dirección cuando no se recibe tráfico de heartbeat de red. Por defecto se utiliza la puerta de enlace de la red de administración. Se pueden especificar hasta 10 direcciones. |
| das.useDefaultIsolationAddress | Determina si, de forma predeterminada, vSphere HA utiliza como dirección de aislamiento la puerta de enlace predeterminada de la red de administración. |
| das.isolationShutdownTimeout | El período que espera el sistema para que se desconecte una máquina virtual antes de apagarla. Esto solo se aplica si la respuesta de aislamiento del host es Shut down VM. El valor predeterminado es 300 segundos. |
| fdm.isolationpolicydelaysec | La cantidad de segundos que espera el sistema antes de ejecutar la directiva de aislamiento una vez que se determina que un host está aislado. El valor mínimo es 30. |
| das.config.fdm.reportfailoverfailevent | Determina si se genera un evento por máquina virtual cuando un intento por parte de vSphere HA para reiniciar una máquina virtual no resulte correcto. El valor predeterminado es 0 (no hay evento). |
| das.iostatsInterval | Cambia el intervalo de estadísticas de E/S predeterminado para la supervisión de la máquina virtual. El valor predeterminado es 120 (segundos). Puede configurarse para cualquier valor igual o superior a 0. Si se configura en 0 se desactiva la comprobación. No se recomiendan valores inferiores a 50. |
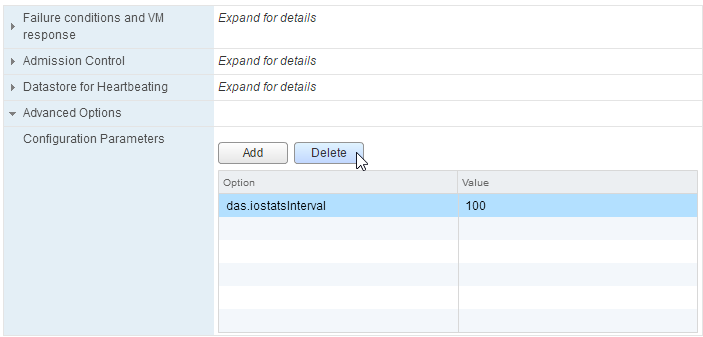
Añadir un valor de configuración avanzada
- Accedemos al cluster
- Accedemos a Manage -> Settings -> vSphere HA
- Pinchamos en Edit
- Expandemos la opción Advanced Options
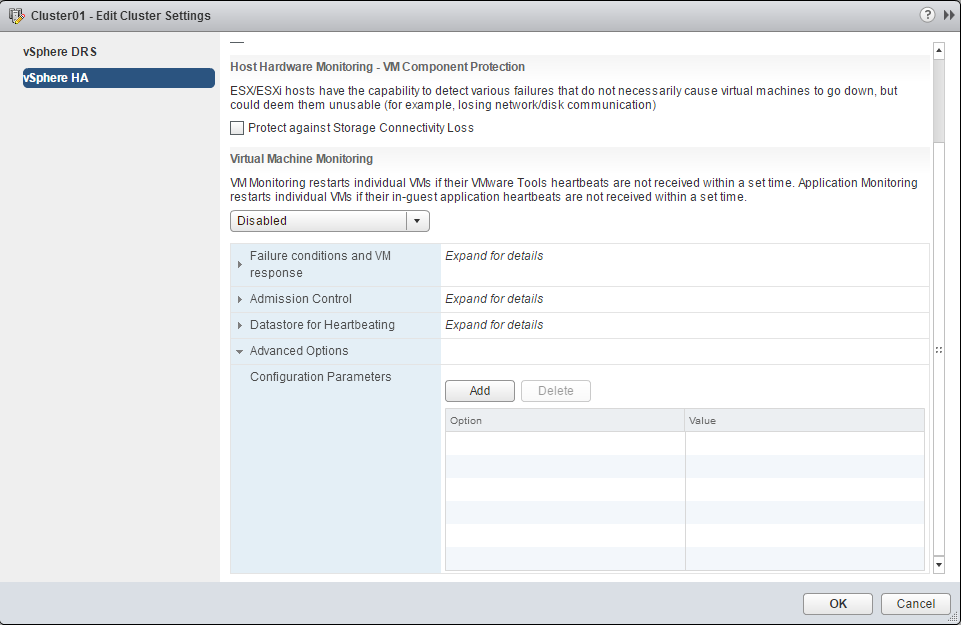
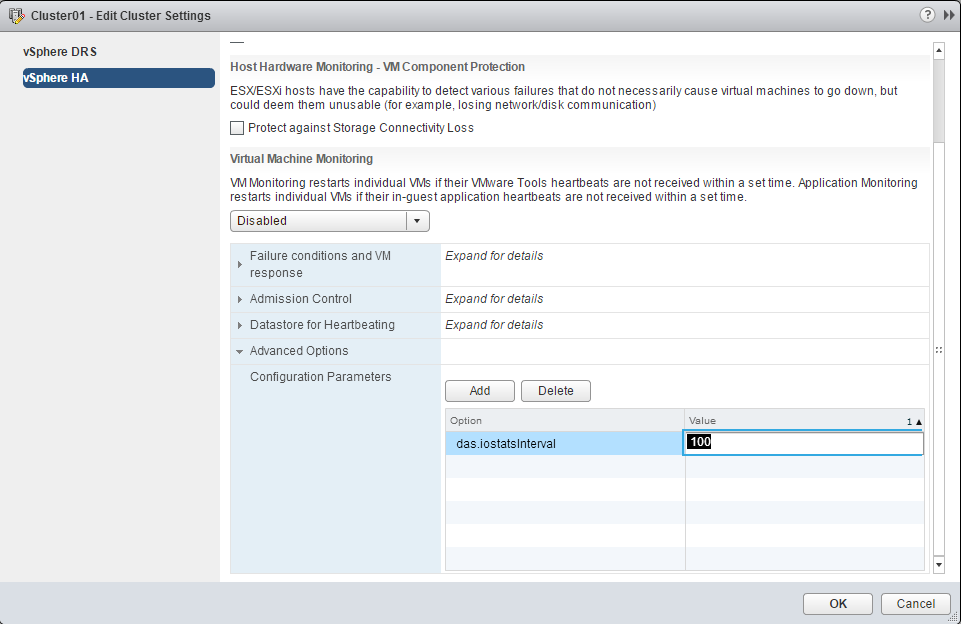
- Pinchamos en el botón Add
- Añadimos la configuración y el valor deseado
Quitar un valor de configuración avanzada
- Accedemos al cluster
- Accedemos a Manage -> Settings -> vSphere HA
- Pinchamos en Edit
- Expandemos la opción Advanced Options
- Seleccionamos la configuración avanzada y pinchamos en Delete
Modify vSphere HA advanced cluster settings
Tras, añadir, eliminar o modificar una opción avanzada, en la mayoría de los casos es necesario que se reconfigure la configuración de HA en los hosts. Para ello seguimos estos pasos:
- Accedemos al cluster
- Accedemos a Manage -> Settings -> vSphere HA
- Pinchamos en Edit
- Desmarcamos la opción Turn On vSphere HA
- Esperamos a que terminen las tareas en los servidores hosts

- Volvemos a acceder a Edit y habilitamos Turn On vSphere HA
- Esperamos a que termine la tarea de configuración
Configure different heartbeat datastores for an HA cluster
Por defecto, HA selecciona 2 datastores para utilizarse como heartbeat a nivel de almacenamiento y poder detectar el estado en el que se encuentran los hosts en caso de problemas de conectividad. En la configuración por defecto, vCenter intenta elegir 2 datastores que estén accesibles por todos los hosts (o la mayoría de ellos) El proceso de selección automático también da preferencia a los datastores VMFS sobre los NFS o intenta utilizar diferentes LUNs o servidores NFS. Aunque no sea la opción recomendada, podemos establecer nosotros que datastores se van a utilizar para heartbeat. Un caso común es en entornos con Metro-Cluster, donde tenemos varias ubicaciones geográficas, y vCenter no es consciente de la ubicación de los elementos.
Para modificar la configuración seguimos estos pasos:
- Accedemos al cluster
- Accedemos a Manage -> Settings -> vSphere HA
- Pinchamos en Edit
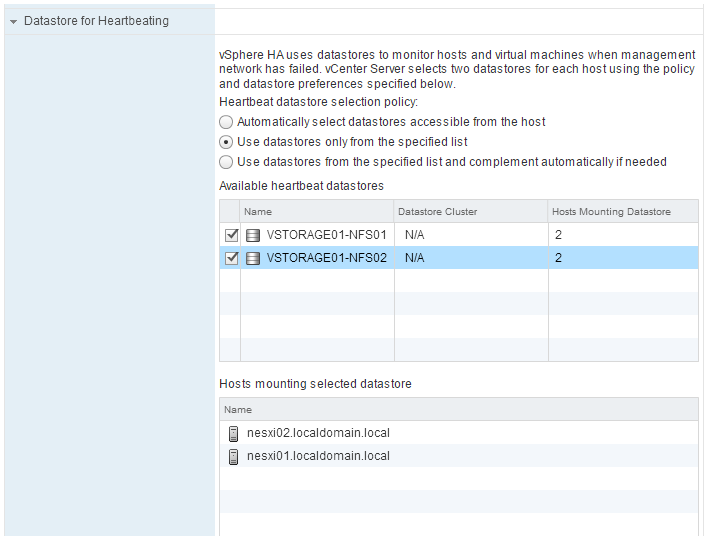
- Expandemos la opción Datastore for Heartbeating
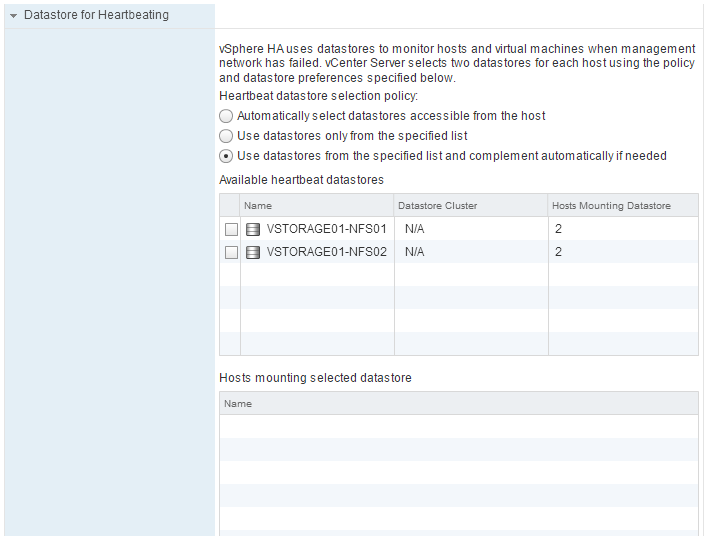
- Tenemos las siguientes opciones dipsonibles:
- Automatically select datastores accesibles from the host: la selección es automática y responsabilidad del servicio vCenter
- Use datastores only from the specified list: se utilizan los datastores seleccionados.
- Use datastores from the specified list and complement automatically if needed: se utilizan los datastores seleccionados y si es necesario, vCenter selecciona otros de forma automática.
- Tras seleccionar la opción a utilizar, seleccionamos los datastores que queremos utilizar
- En el apartado Hosts mounting selected datstores podemos ver los datastores que tienen acceso al datastore seleccionado.
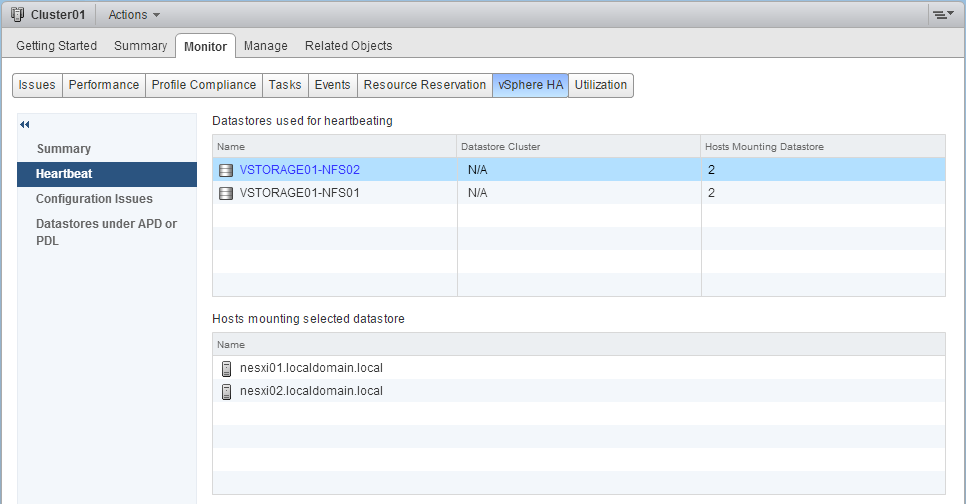
- Tras modificar la configuración, también podemos ver la configuración en Monitor -> vSphere HA -> Heartbeat
Apply virtual machine monitoring for a cluster
La opción VM monitoring de vSphere HA permite reiniciar máquinas virtuales que no estén respondiendo correctamente. Para detectar si una máquina virtual no está funcionando correctamente, se realizan dos comprobaciones:
- Heartbet de las Vmware Tools que se ejecutan en la propia máquina virtual
- Actividad de Entrada/Salida (disco o red). VMware detecta si se ha producido activdad de disco o de red durante los 120 segundos anteriores (este valor se puede modificar con la opción avanzada das.iostatsinterval) Si se cumplen las dos condiciones, es posible que la máquina virtual tenga un problema por lo que reiniciarla puede resolverlo.
Es necesario configurar la sensibilidad para determinar que la máquina virtual tiene un problema.
Para modificar la configuración seguimos estos pasos:
- Accedemos al cluster
- Accedemos a Manage -> Settings -> vSphere HA
- Pinchamos en Edit
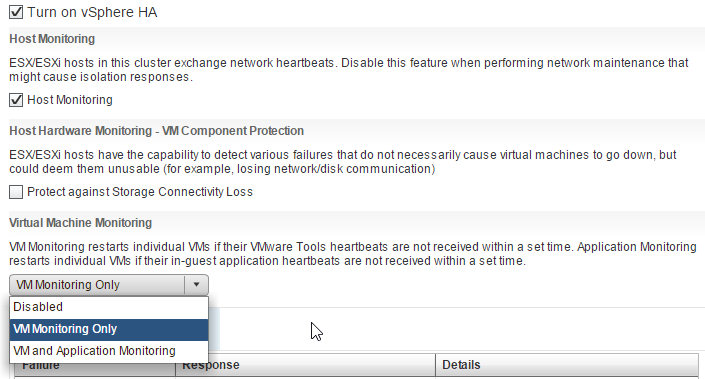
- Accedemos a la opción Virtual Machine Monitoring y seleccionamos la configuración desdeada:
- Disabled
- VM Monitoring Only
- VM and Application Monitoring: se monitoriza también a nivel de aplicación, no sólo de máquina virtual (es necesario disponer del SDK correspondiente)
- Expandemos la opción Failure Conditions and VM response
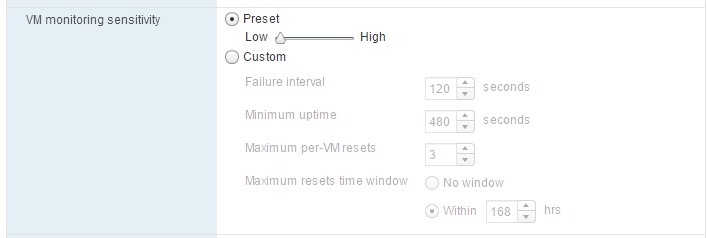
- Definimos la sensibilidad de la detección de problemas. Las configuraciones predeterminadas tienen estos valores
| Configuración | Failure interval | Minimum Uptime | Maximum per-VM resets | Maximum resets time window |
|---|---|---|---|---|
| Low | 120 segundos | 480 segundos | 3 | 168 horas |
| Medium | 60 segundos | 240 segundos | 3 | 24 horas |
| High | 30 segundos | 120 segundos | 3 | 1 hora |
Podemos definir los siguientes valores:
- Failure interval: Tiempo en el que si no hay eventos se identifica una máquina como fallida.
- Minimum Uptime: tiempo mínimo de espera entre comprobaciones con la máquina virtual encendida.
- Maximum per-VM resets: máximo número de reinicios que HA realiza en el tiempo indicado.
- Maximum resets time window: ventana de tiempo en la que se determina el máximo de reinicios permitidos por máquina.
Un valor de sensibilidad alto (High) da como resultado un menor tiempo en la conclusión de que la máquina virtual tiene un error, y una mayor agresividad en cuanto al reinicio de las máquinas virtuales.
Configure Virtual Machine Component Protection (VMCP) settings
Virtual Machine Component Protection (VMCP) es una nueva funcionalidad de vSphere 6 que puede detectar errores de acceso al almacnemiento y realizar tareas automáticas de recuperación de máquinas virtuales. VMCP detecta dos tipos de eventos:
- Permanente Device Loss (PDL): es una pérdida de acceso irrecuperable
- All Paths Down (APD): es una pérdida de acceso temporal o desconocida
Para configurar VMCP en un cluster seguimos estos pasos:
- Accedemos al cluster
- Accedemos a Manage -> Settings -> vSphere HA
- Pinchamos en Edit
- Habiliamos la opción Host hardware monitoring - VM Component Protection -> Protect Against Storage Connectivity Loss

- Expandemos la opción Failure Conditions and VM response

- Configuramos los siguientes valores
- Response for Datastore with Permanent Device Loss (PDL): respuesta cuando se produce un evento PDL
- Disabled
- Issue Events
- Power off and restarts VMs
- Response for Datastore with All Paths Down (APD): respuesta cuando se produce un evento APD
- Disabled
- Issue Events
- Power off and restarts VMs (conservative): No reinicia la máquina virtual a menos que sepa que existe un host disponible en el que reinciarla. En la mayoaría de las situaciones esta es la opción recomendada.
- Power off and restarts VMs (aggresive): reinicia la máquina virtual en todos los casos. Pueden existir situaciones donde esta opción sea la recomendada (por ejemplo en una configuración de Metro-Cluster Yellow-Bricks: Conservative vs Aggressive for VMCP APD response)
- Delay for VM failover for APD: tiempo de espera hasta ejecutar la acción definida para eventos APD
- Response for APD recovery after APD timeout: respuesta tras superar el timeout APD
- Disabled
- Reset VMs
- Response for Datastore with Permanent Device Loss (PDL): respuesta cuando se produce un evento PDL
Relación de eventos en el tiempo ante una situación APD
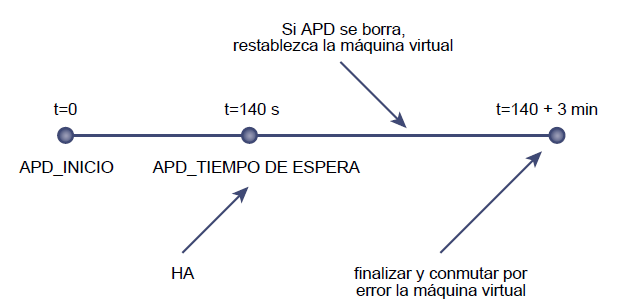
- t=0: se detecta el evento APD. Si es un evento PDL, en este momento ya se inician las tareas para recuperar las máquinas virtuales (reinicio)
- t=140s: Se ha llegado al tiempo definido como Timeout
- t= entre 140s y 320s: es elt tiempo definido por el timeout (140s) más el tiempo de Delay definido (3 minutos o 180 segundos) Si se recupera el almacenamiento durante este periodod de tiempo se realiza la acción definida en Responde for APD recovery after APD timeout
- t=320s: se inicia la tarea de recuperación
Implement vSphere HA on a Virtual SAN cluster
vSphere HA es totalmente compatible con Virtual SAN aunque hay que tener en cuenta varios aspectos:
- Al crear el cluster VSAN es necesario primero habilitar Virtual SAN y luego habilitar y configurar vSphere HA.
- HA utiliza la misma red que Virtual SAN para hearbeat. Es necesario utilizar una dirección de aislamiento n la red VSAN y se recomienda configurarla de forma manual con las opciones avanzadas (das.isolationAddress0 y das.useDefaultIsolationAddress)
- En Virtual SAN no se utiliza el concepto de Heartbeat Datastores.
- En Virtual SAN la ubicación de los archivos utilizados por HA se ubica en el espacio de nombres de la máquina virtual, no en el raiz del datastore.
Explain how vSphere HA communicates with Distributed Resource Scheduler and Distributed Power Management
HA es una operación que se realiza a nivel de host, mientras que DRS y DPM son operaciones que se realizan a nivel de vCenter.
Casos en los que HA se comunica con vCenter para utilizar DRS y DPM:
- HA puede solicitar a DRS que "desfragmente" el cluster, de forma que, por ejemplo, se puede dar el caso de tener recursos suficientes para reiniciar una máquina virtual, pero al no estar disponibles en un host, sea necesario invocar DRS para que rebalancee la carga y un servidor host pueda disponer de los recursos para que HA pueda completar el reinicio de la máquina virtual.
- Cuando se configura Admission Control con la opción de Specify Failover hosts, los servidores seleccionados no son utilizados por DRS en el rebalanceo del cluster.
- Cuando existen shares definidos a nivel de máquina virtual, cuando las máquinas virtuales se reinician, estas se ubican de forma inicial, en el Resource Pool raiz del cluster, asignandoles un valor de share predeterminado. Es cuando se vuelve a invocar DRS (cada 5 minutos) cuando se reubican las máquinas en su Resource Pool original y con los shares que tenían originalmente configurados.
- Si DPM está habilitado, se tiene en cuenta la configuración de Admission Control, para evitar que se puedan poner en standby hosts que puedan violar la política definida por Admission Control. Si se produce un evento HA, DPM puede arrancar hosts si es necesario para poder tener más recursos y reiniciar las máquinas virtuales.